

Build a House Sale Price prediction model with Azure Machine Learning Studio
Setup and Instruction Guide
This blog is based on the Tech Tomorrow video hosted by Microsoft’s Stephanie Visser en Stijn Buiter. They explain how to build a House Sale Price prediction model with Azure Machine Learning. This model predicts the possible sale price of a house in Ames, Iowa. The corresponding dataset is available on Kaggle, as part of the House Prices: Advanced Regression Techniques competition and the data has been elaborated by Dean de Cock, who wrote also a very inspiring on how the handle the Ames Housing data.
The point of this blog is to offer you a step-by-step instruction guide, so you can build your own model. It is not intended to be a deep-dive into model design, validation and improvement. If you want to learn more, please check out our Principles of Machine Learning, Applied Machine Learning or other Data & AI courses.
This blog contains the following parts:
- Setup your Azure ML environment
- Build your House Sale Price prediction model in 10 steps
What You’ll Need
To perform the tasks, you will need the following:
- A Windows, Linux, or Mac OSX
- A web browser and Internet
- Time and energie 🙂
1. Setup your Azure ML environment
There are several options to start with Azure ML: https://azure.microsoft.com/en-us/services/machine-learning/

If you don’t have an Azure account already, we recommend you to use the Free Workspace option. Therefore, you would have to sign up for a Microsoft account. If you don’t have one already, you can sign up for one at https://signup.live.com/
2. Build the House Sale Price prediction model in 10 steps
I would highly recommend you to get a better understanding of the data first. You can find more information on the House Prices: Advanced Regression Techniques competition site, and it would be even better to read the article about the Ames Housing data (De Cock, 2011).
Create a new experiment
Start with downloading the starting experiment, which contains the training data from Kaggle: Starting experiment on Cortana Intelligence Gallery. From the gallery, you can open the experiment in your own Azure Machine Learning Studio by clicking on the “open” button.
This will open a window where you have to sign in with your Azure account to access the Azure Machine Learning Studio. You will be asked in to which environment you want to copy this model. After selecting the environment (i.e. your free workspace) the model will be opened. If the model doesn’t open, you can go to the “EXPERIMENT” section, and you will find it there. Click on it and it will open. You see 2 modules: one with the Ames Housing Data and a second Execute R Script block.
Explore the data
Before we are going to build the model, we are first going to inspect the data:
- This new experiment has the “In draft” status (top corner right). Click on RUN (menu below). You will have to wait until the model is finished running before you continue. To visualize the output of the dataset, right-click on the output port of the Ames Housing Data module and select Visualize.
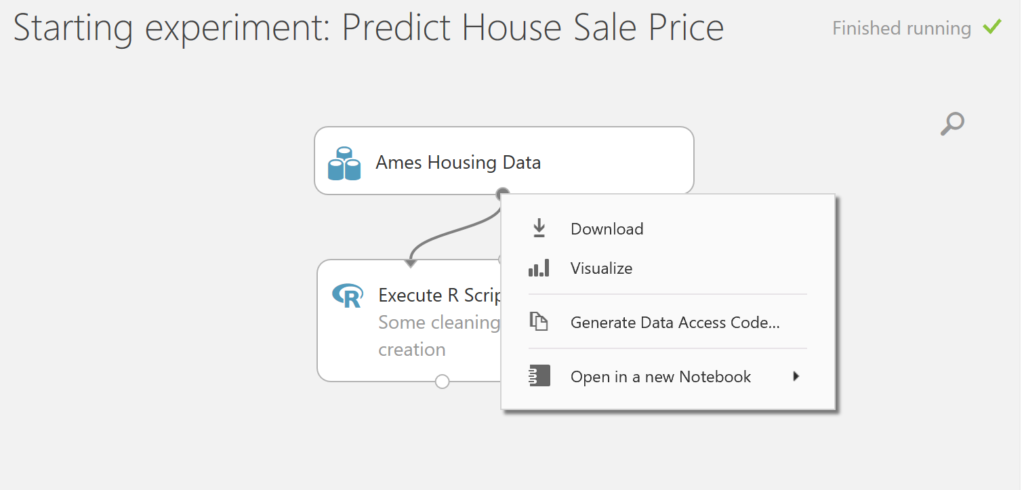
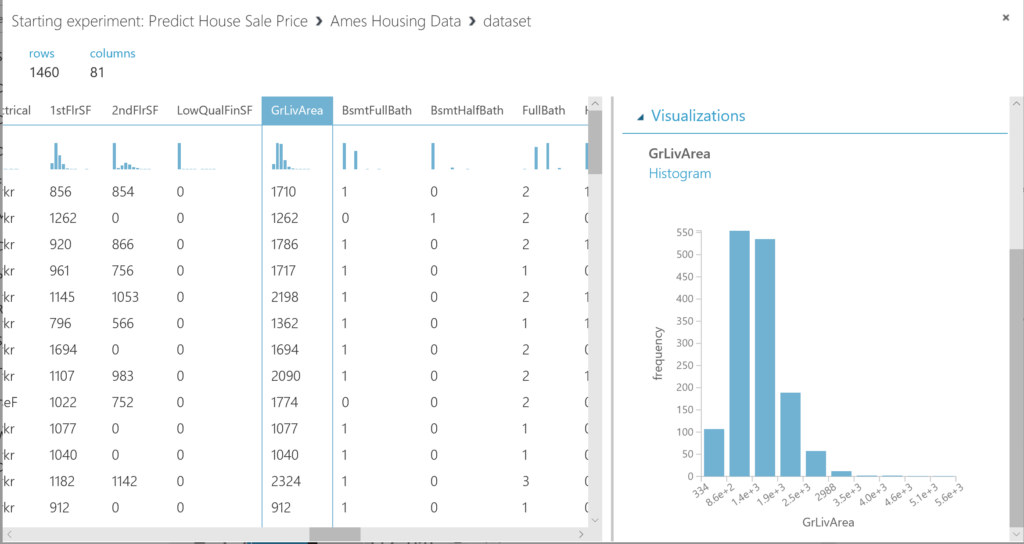
This dataset contains 1460 rows and 81 variables. As said before, you can find all the information about the variables in the paper of Dean de Cock. A detailed document about the variables can be found there as well.
For now, we will focus on just a few variables to get you started. Let’s start with some basic assumptions. We assume that the size of a house matters, as well as the quality of it, and the neighborhoud (location, location, location!). So let’s start there.When reviewing the size, we see several variables regarding the size: Now you can review the data it contains by selecting the columns. Note that the dataset contains the following variables: GrLivArea (Above grade (ground) living area square feet) and TotalBsmtSF (Total square feet of basement area). We start with inspecting GrLivArea. You can inspect this variable by selecting the column:
Clean and prepare the data
- We see that this variable is skewed and has some outliers. So our first step is to remove these outliers. We use the mean of the GrLiveArea, and calculate the standard deviation, and decide to keep all the observations within a range of +-2 standard deviations to the mean.
Note: if you want to refresh you knowledge about statistics, please feel free to explore the Essential Statistics for Data Analysis using Excel course.We see various types of sales (SaleCondition). In this case, we are only interested in “normal” sales.Finally, there is no variable available which indicates the total footage of the house, so we create one by adding up GrLivArea and TotalBsmtSF and we call this new variable TotalSqFoot.These 3 steps are done in the module Execute R Script.
Note: if you want to learn more about R you can follow our online Introduction to R for data science course, or come to the next classical session in collaboration with Vijhart IT-Opleidingen.
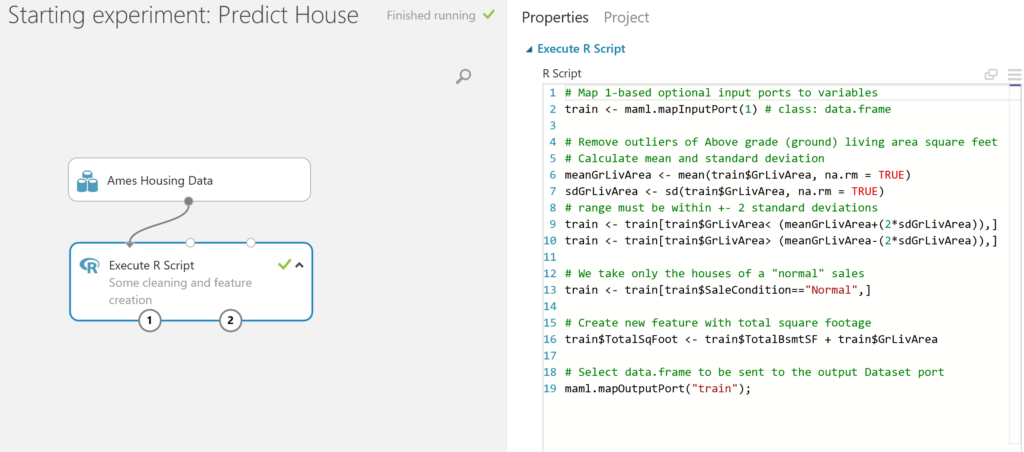
- After cleaning the data and creating a new variable, we can select the variables we want to use in this model with the Select Columns in Dataset module. Drag this module on the canvas and connect the output port of the Execute R Script module to the input port of the Select Columns in Dataset module. You will see that a red circle with an exclamation mark will appear in this module, as we haven’t selected any columns yet.
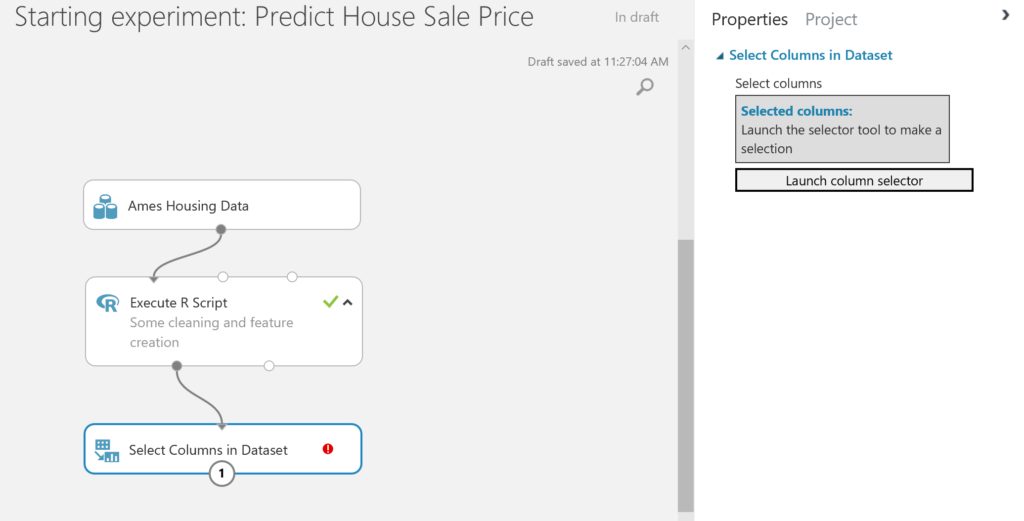
To solve this, select the module and click on the Launch column selector to start selecting the variables:
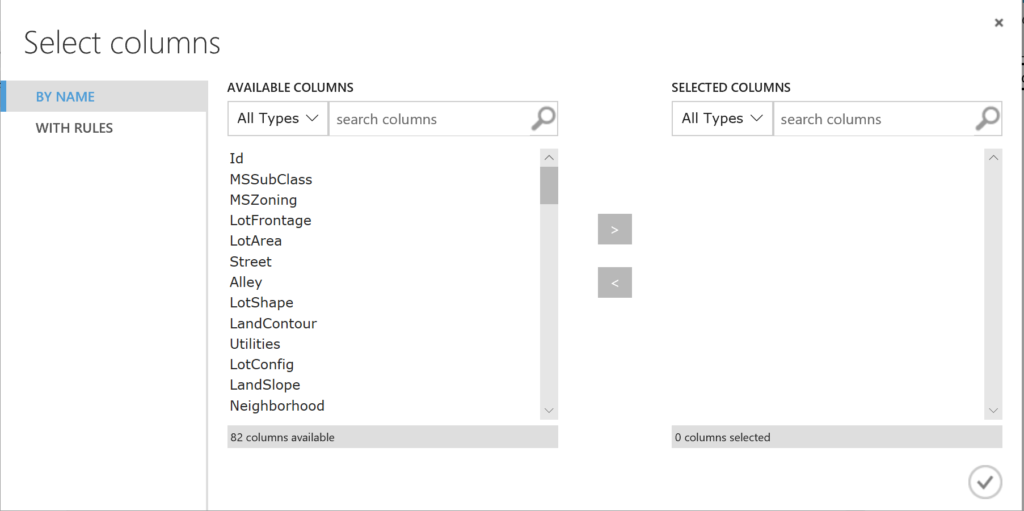
We select the variables: MSZoning,OverallQual, OverallCond, TotalBsmtSF, GrLivArea, SalePrice, TotalSqFoot, and Neighborhood.
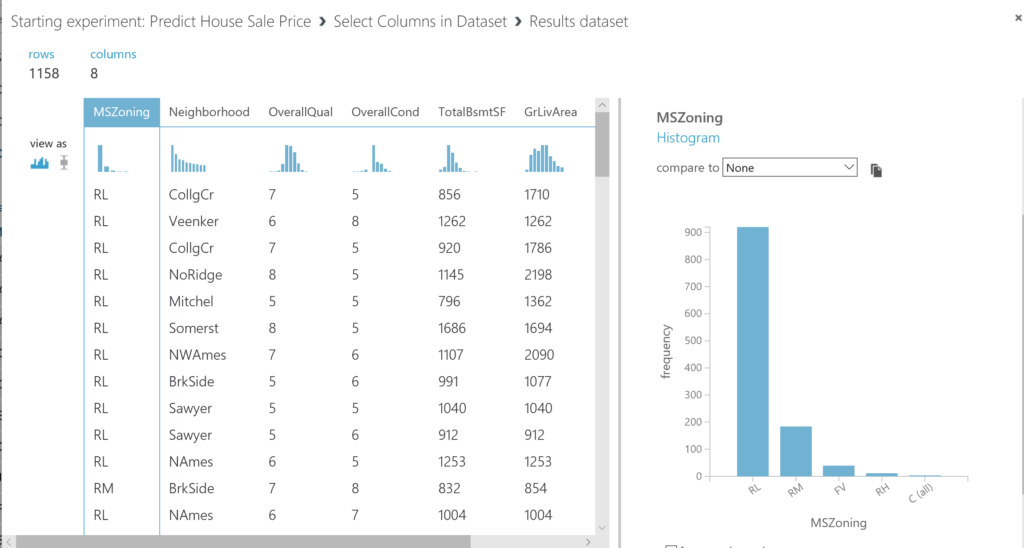
Run the model and check the data again. You will now see that you only have the selected variables, and, because of the prior cleaning you have 1158 rows left. Besides, we observe that we have 2 categorical variables: MSZoning and Neighborhood.
- To make sure that the categorical variables are treated as such in Azure Machine Learning studio, we use the Edit Metadata module, select MSZoning and Neighborhood by launching the column selector, and make them categoricals and features:
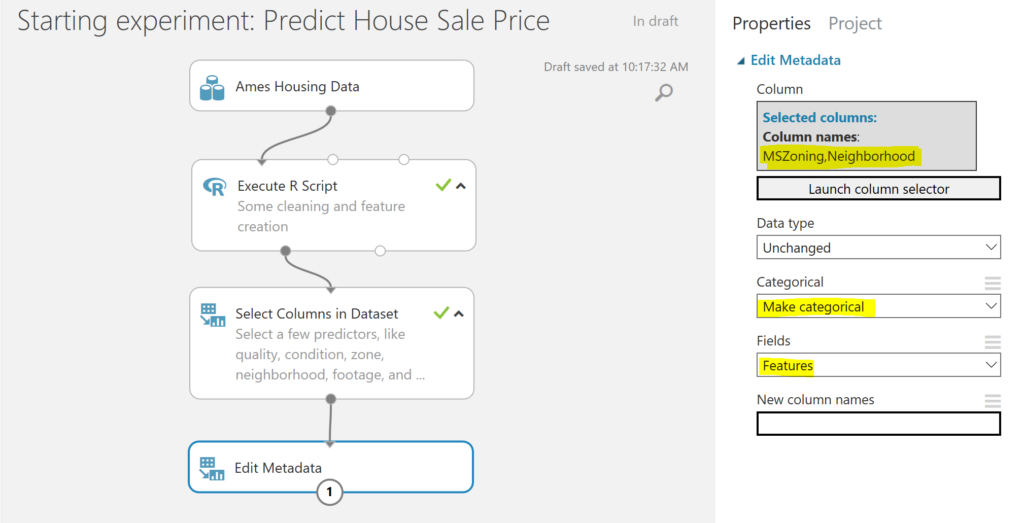
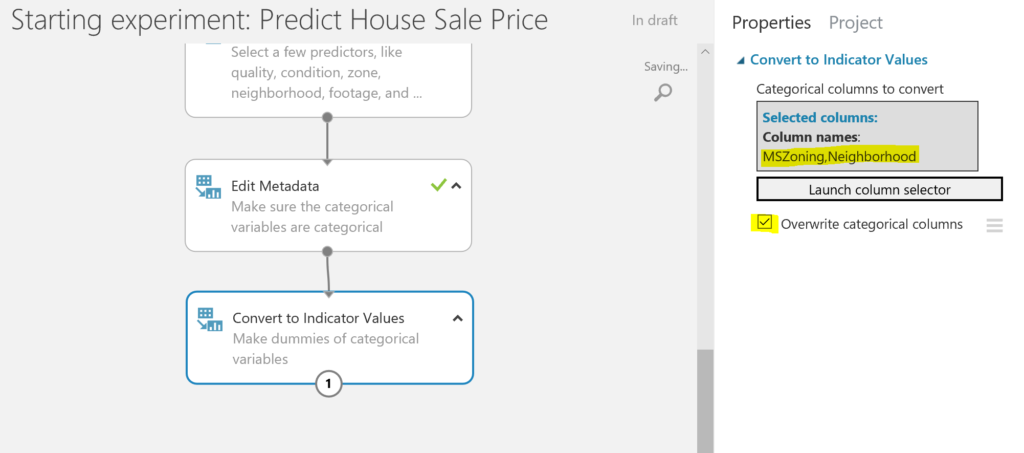
- Due to the fact that we want to predict the house sale price, we will use a regression model. Therefore, we would have to transform the categorical variables into dummy variables. Every category dummy will indicate whether an observation has that specific category of that variable, i.e. is MSZoning “RL” or not, and will set this catagory dummy to 1 (yes, observation is MSZoning-RL) or 0 (no, observation in not MSZoning-RL). This can be done easily with the Convert to Indicator Values module. We select MSZoning and Neighborhood launching the column selector, and we overwrite the initial variables as we no longer need them.
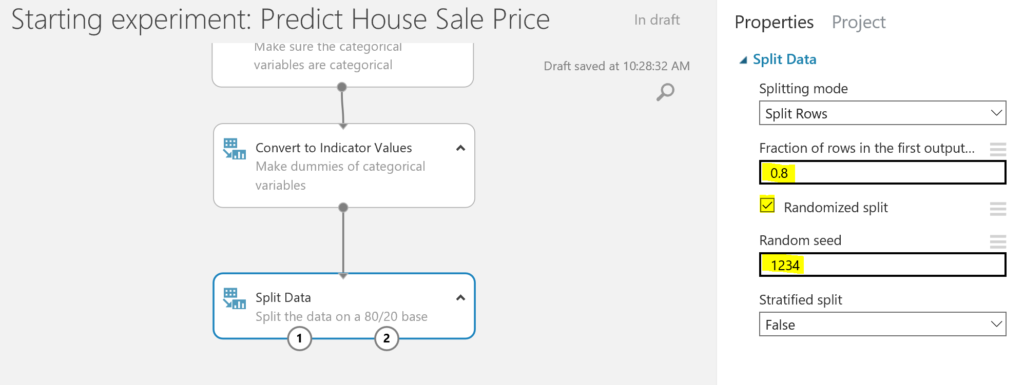
- Before training the model, we make sure we split the data into a training dataset and a test dataset. We will train the model with the training dataset, and we will test how good the model performs with the test dataset.
To split the data, we use the Split Data module, and we split the set into 80% training data and 20% test data. There is no fixed rule for this, but many people use a 70/30 or a 80/20 split. Besides we will set a seed so we can reproduce this process later on.
Build the model
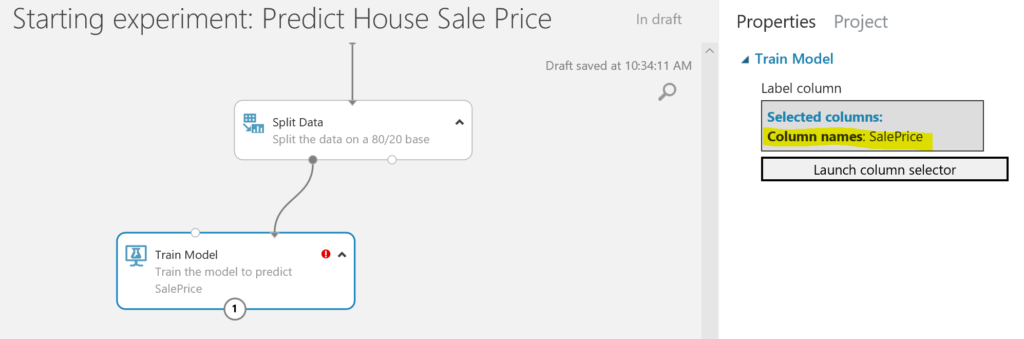
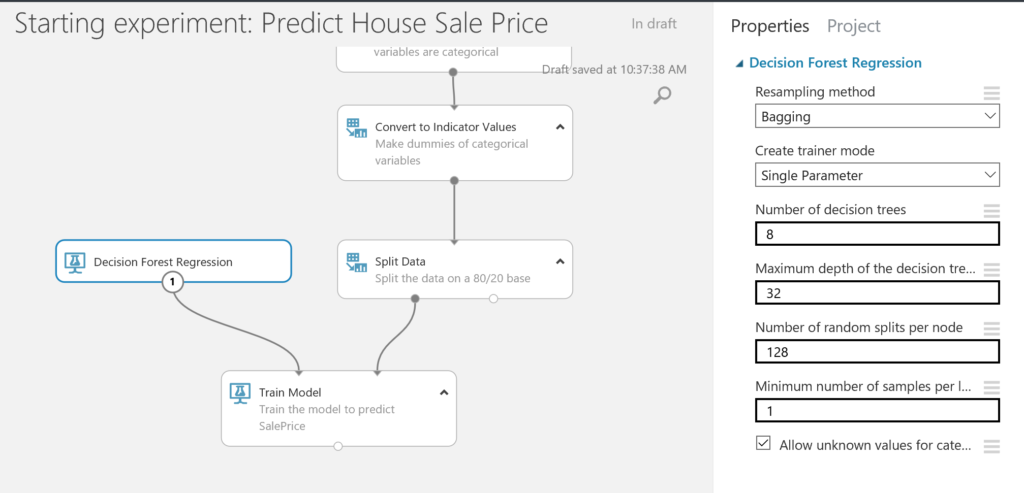
- Finally, we are ready to train the model, using the Train Model module. We select SalePrice as the variable we want to predict. As you can see, there is still an exclamation mark visible. This is because we have not selected an algorithm to train the model with. We will do this in the next step.
- In this case, we will use a regression algorithm to train the model with. There are various options, but let’s just take the Decision Forest Regression for now. We leave the initial settings as generated by Azure Machine Learning Studio. Remember to click on RUN after adding new modules to the canvas.
Note: if you want to dive deeper into machine learning, we have several courses available like Principles of Machine Learning and Data Science Essentials.
- We are now ready to score the test dataset by using the Score Data module. This means that we will use the trained model to make a prediction of the house sale price of the test data. We want to add the scoring result to the train data, so we can evaluate the data in the next step.
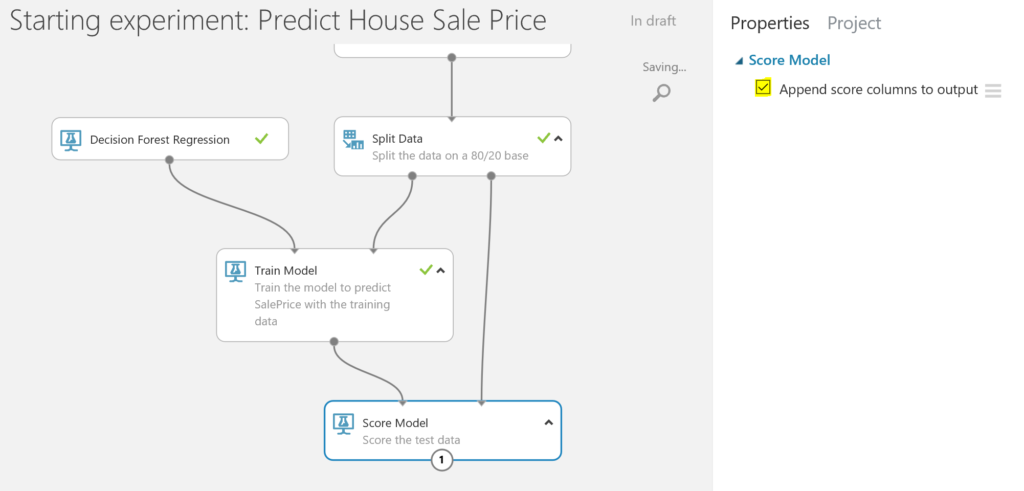
Evaluate the model
- The last step is evaluating how the model performs. We use the Evaluate Model module to run this check.
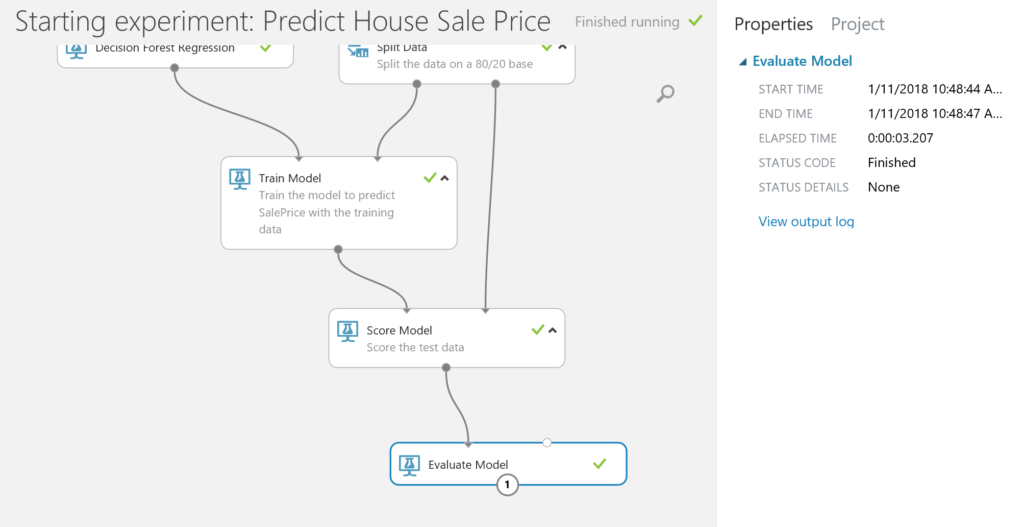
When we visualize the result (right-click on Evaluate Model output port) we find a coefficient of determination of 0.84, which is not bad at all! Remember that we selected only a few predictors, and that we did very little with the data.
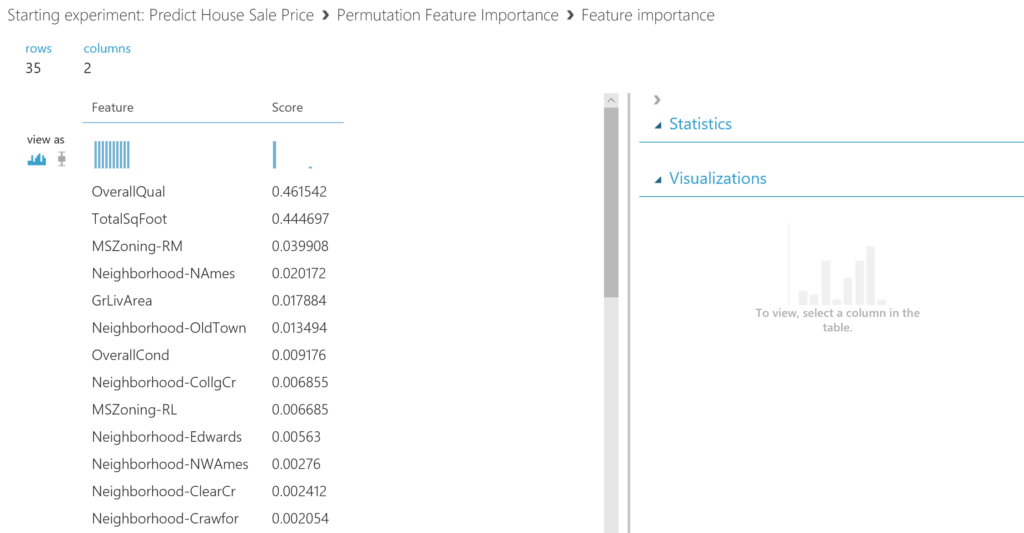
 BONUS: if you want to see which features had the highest importance for the model, you can use the Permutation Feature Importance module. We connect this module to the trained model and use the test data to calculate the importance of the features. We set a seed for reproducibility. As we are -in this case- interested in the coefficient of determination, we select this option:
BONUS: if you want to see which features had the highest importance for the model, you can use the Permutation Feature Importance module. We connect this module to the trained model and use the test data to calculate the importance of the features. We set a seed for reproducibility. As we are -in this case- interested in the coefficient of determination, we select this option:
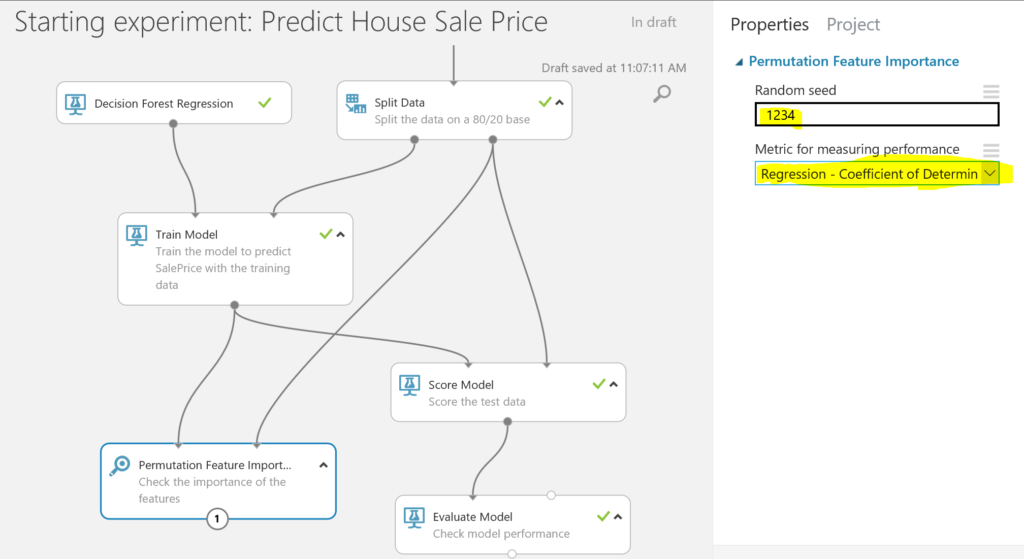
The outcome shows us that that the overall quality of the house is very important, as well as the total footage. Regarding the zone, we see that Residential Medium Density (MSZoning-RM) is a nice area when it comes to selling you house.
This is it for now! In case you got stuck, you can also download the complete Predict House Sale Price model from the Cortana Intelligence Gallery.
In future blogs, we will cover some more deep-dive modelling, as well as publishing models. If you have any suggestions for a blog or questions, please let us know!
Very informative, Thank You. Would you please share some more detail about model prediction as in this example we have taken only 6 columns what if we take all of the columns or at least maximum columns?
Hi Abdul, thanks for your comment. This was just an example, and I would recommend you to try to build your own model, and used the columns based on logic. After that you can start pruning the model.